
Опыт построения внутреннего SOC: плюсы, минусы, подводные камни
Введение
Мы приступили к построению внутреннего центра мониторинга информационной безопасности (Security Operation Center, SOC) в 2018 году, основной целью ставили перед собой – создать такую систему мониторинга, чтобы мы первыми узнавали, какие события в рамках информационной безопасности происходят в инфраструктуре банка и могли незамедлительно реагировать на инциденты. У нас на тот момент была сформирована команда, которая умела строить IT-инфраструктуру и поддерживать ее. Кроме того, у нас была группа реагирования на компьютерные инциденты с талантливыми специалистами.
Цели и задачи
Далее мы сформулировали первоочередные задачи, которые перед нами стояли: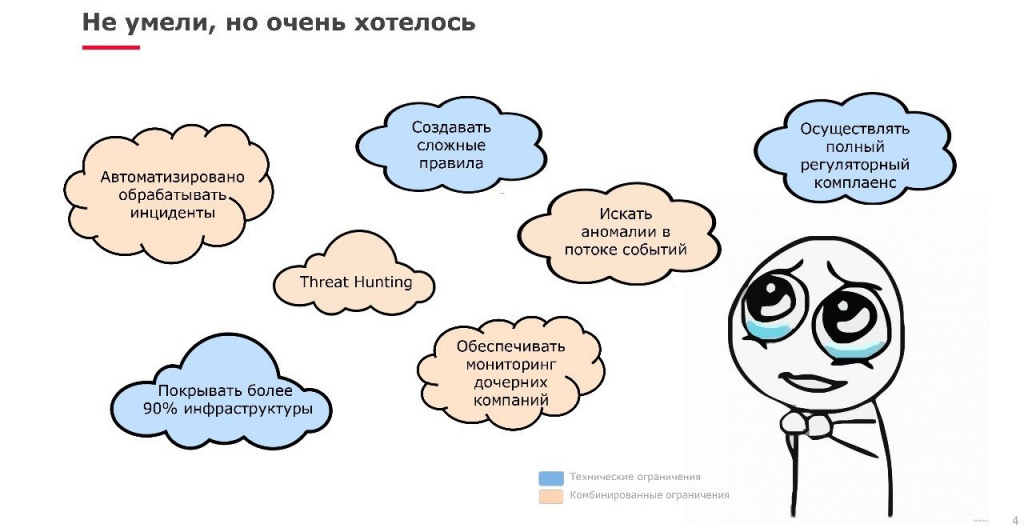
Не буду детально останавливаться на каждой задаче, но хотел бы обратить внимание на то, что у нас есть пул дочерних компаний, которые тоже необходимо было включить в контур мониторинга, предложив им ту же сервисную модель, которая работает внутри МКБ.
Подготовка к проекту
С чего мы начали подготовку к проекту? Во-первых, пригласили в команду высококлассного архитектора, его задачей было спроектировать SOC в части технологий и придать ему те контуры, которые он сейчас имеет. В рамках подготовки также был определен руководитель SOC, давно работающий в банке и понимающий многие происходящие процессы. Во-вторых, мы произвели тщательный расчет серверных мощностей, затем создали архитектуру и достаточно кропотливо подобрали ПО, ставшее основой SOC. Надо сказать, нам даже удалось сэкономить на ПО, поскольку мы отказались от очень дорогой SIEM-системы, приобретенной банком ранее. И самое главное – это грамотный расчет службы по подбору персонала, потому что все мы прекрасно знаем, что SOC – это люди, технологии и процессы. И люди – это наиболее важная часть.
Обоснование проекта
В рамках подготовки к запуску своего центра мониторинга информационной безопасности мы естественно сравнивали его предполагаемую эффективность с коммерческими SOC. Мы очень плотно поработали с такими компаниями как «Ангара», «Бизон», «Джет» и другими. Работали честно, у нас не было намерения любой ценой сделать все самостоятельно, мы были готовы привлечь и внешние SOC. В итоге, в сравнении с самым бюджетным предложением, у нас стоимость владения SOC за 4 года получилась ниже на 40 процентов. Во-первых, мы оценили все риски, в том числе остаточные. Мы оценили их количественно, и это стало своеобразным экономическим базисом для утверждения проекта. Во-вторых, мы провели детальный анализ как рынка SOC, так и банковского рынка в части мониторинга и реагирования на инциденты: мы изучили, как коллеги из крупнейших банков подходят к решению проблемы. В-третьих, мы очень точно просчитали общие расходы – так называемую совокупную стоимость владения (Total cost of ownership, TCO). Стоимость владения мы показали правлению, чтобы бизнес четко понимал, что сколько стоит и что он получает за обозначенный бюджет.
План реализации
Дальше мы создали план реализации проекта, дорожную карту. Тут важно отметить, что работы по созданию инфраструктуры заняли достаточно большое количество времени. В план вошли не только работы по подключению всех инфраструктурных элементов, но и создание свода правил по реагированию на события. Например, применительно к операционным системам, правила для Windows мы сейчас переписываем, используя MITTRE и другие признанные ИБ-сообществом практики. У нас их получается порядка 130, это довольно много, все их нужно смотреть, имплементировать, выверять, тестировать. Поэтому, если вам кто-то скажет, что справился за три месяца, то будьте уверены: либо речь идет об очень маленькой и гомогенной инфраструктуре, либо это неправда.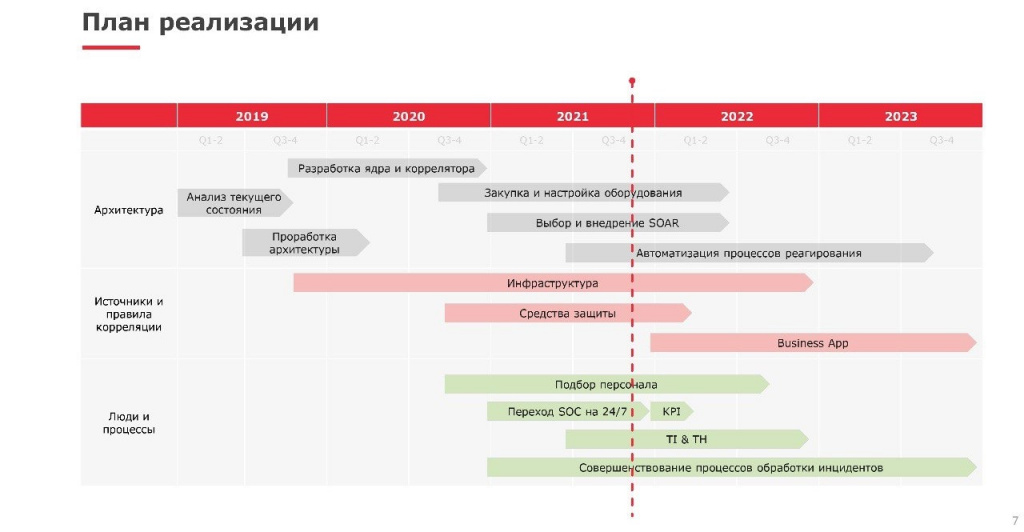
Используемые технологии
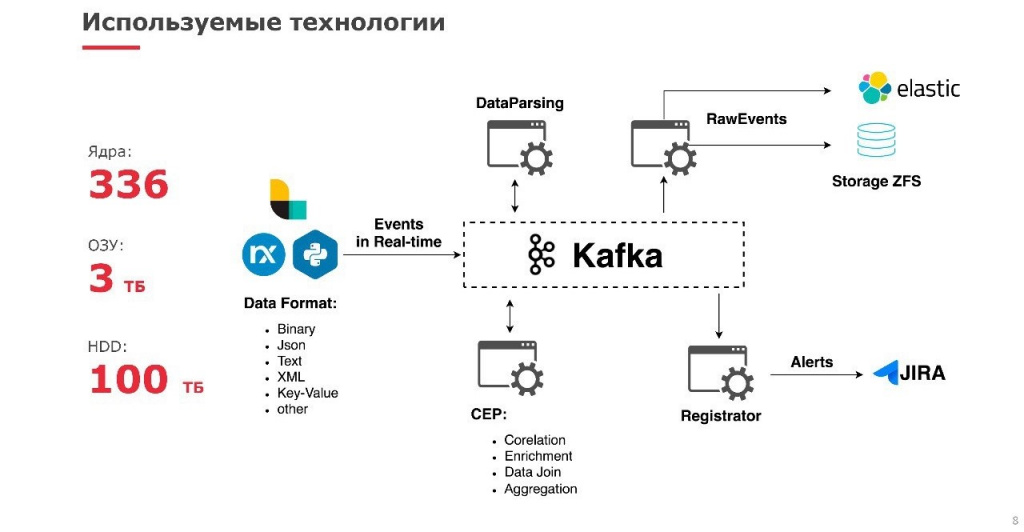
Мы купили большой объем оборудования, в результате получили 336 ядер, 3 терабайта оперативной памяти и около 100 терабайт дисковой подсистемы. Но чтобы завершить задуманную архитектуру, нам предстоит расширить мощности, в первом полугодии 2022 года мы ожидаем очередную крупную поставку «железа». Важная часть работы SOC – предварительная обработка событий. Это позволяет снизить нагрузку на ядро SOC и сделать, насколько это возможно, распределенным прикладной функционал. Мы сделали очереди на базе Kafka и, соответственно, те инциденты, которые возникают, обрабатываются с помощью Kafka, потом у нас происходит обогащение, затем сравнение и итоговое формирование инцидента. В основном мы сознательно используем программное обеспечение с открытым исходным кодом (opensource) либо собственную разработку на Python. Это снимает с нас дополнительные экономические ограничения для перехода на более современные технологии.Сырые события попадают из источников событий в файловую систему на ZFS, а те, которые нужны для активного использования, – на ELK-стек. Для операторов и менеджеров существует Jira, которая демонстрирует инциденты и по сути является единым окном для всего SOC.
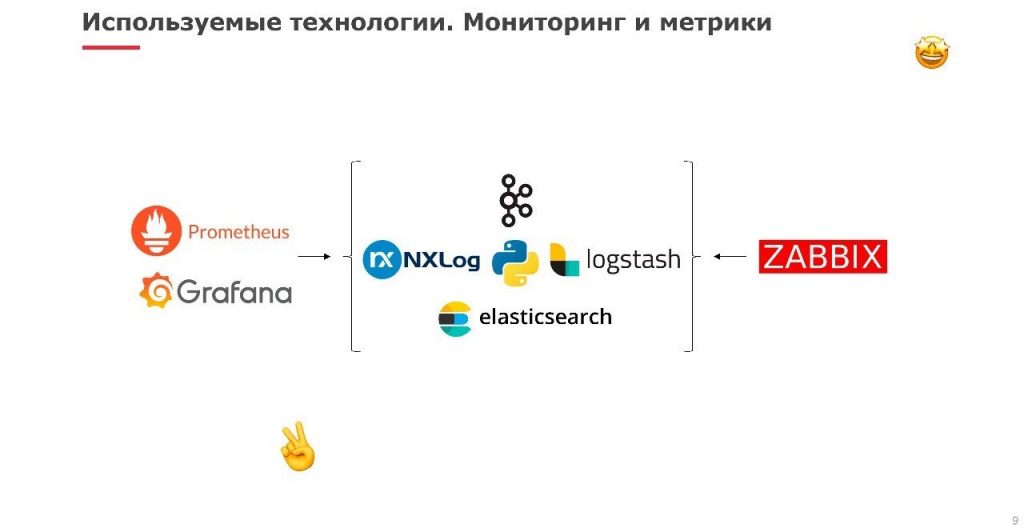
Теперь, что касается мониторинга и метрик. Тут важно понимать, что мы изначально делали акцент на том, чтобы SOC был доступен. И один из первых наборов правил, которые мы создаем, – это правила на случай, если события перестали поступать, либо SOC прекратил функционировать. Это важно, иногда про это забывают. Соответственно, метрики того, как что работает – это тоже неотъемлемый атрибут, чтобы осуществлять эффективную поддержку. Мы сразу заострили на этом внимание, потому что можно бесконечно двигаться в развитии, но, если ты построил одну стену дома, потом строишь другую, а предыдущая тем временем разваливается, это, согласитесь, не способствует завершению строительства в целом.
Промежуточные результаты
Что мы сейчас умеем? Мы умеем фильтровать 20-40 процентов потока в зависимости от коллекторов и платформ от входящих событий. Умеем обрабатывать объем событий – примерно 150 гигабайт в сутки. У нас средний среднесуточный поток данных – 4 тысячи событий в секунду, и соответственно, пиковый поток на источник – чуть больше 5 тысяч. Есть достаточно распространенные платформы, с которыми мы умеем «дружить» и получать события. Есть 117 готовых правил, есть 4 инфраструктуры, подключенные к МКБ.
Есть еще и процедуры, связанные с реагированием. Вот статистика, сколько событий мы можем обработать в зависимости от режима работы. На режим 24/7 мы перешли совсем недавно, поэтому цифры по достаточно распространенному режиму 9/5 вполне актуальны.

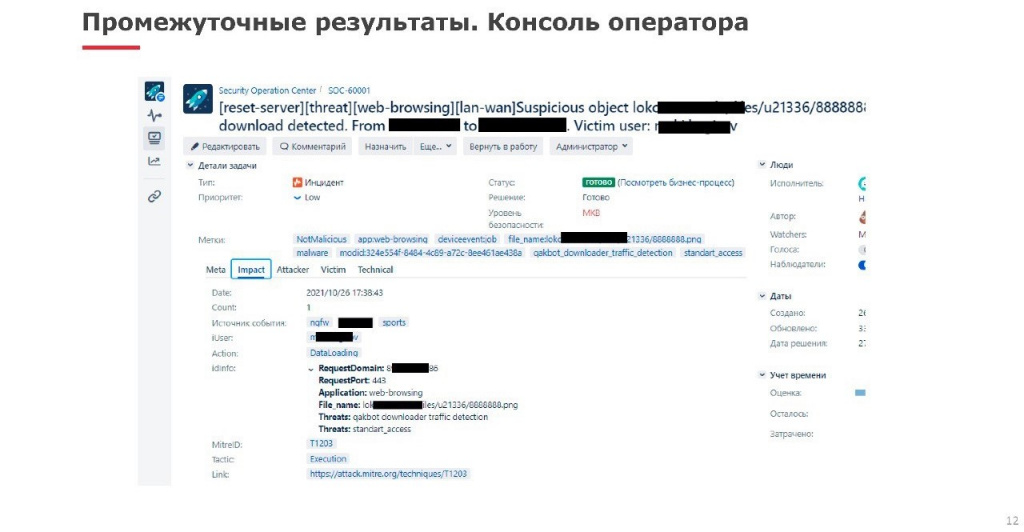
Чтобы показать промежуточные результаты, ниже представлена консоль оператора. Тут происходит качественное обогащение: к каждому инциденту мы стараемся прикрепить не просто учетную запись, но еще и пользователя и описание хоста из CMDB, чтобы понимать, с кем общаться, когда из-под учетной записи выходят какие-то негативные события и оценивать критичность инцидента. Кроме того, там есть различные ссылки, чтобы можно было быстро смотреть связанные с инцидентом события.
Плюсы, минусы, подводные камни
Теперь, собственно, про плюсы-минусы и подводные камни. Какие плюсы? Стоимость – это очевидно, потому что 40 процентов стоимости владения по сравнению с коммерческими SOC – впечатляющий показатель. Скорость реагирования. Мы точно реагируем быстрее, потому что скорость реагирования тесно взаимосвязана с другим свойством – управляемостью. А управляемость у нас, понятно, намного выше. Я всегда могу прийти и сказать: «Коллеги, давайте ту или иную процедуру поправим и сделаем лучше». В сторонний SOC я, наверное, тоже могу внести правки и усовершенствования, но в рамках соответствующего договора, и совершенно точно речь пойдет о месяцах или годах и о модификации дорожной карты организации. С учетом того, что у стороннего SOC клиентов много, индивидуальные процедуры могут иметь место, но не думаю, что на постоянной основе.
Какие минусы? Скорость реализации. В общем-то, мы сразу настраивались на то, что этот проект займет несколько лет. Сейчас мы создали базис, который умеет всё. Этот год мы посвятили очень важным вещам: написанию ядра, подключению ключевой инфраструктуры, созданию и отладке коллекторов и т. д. То, что в ходе работы возникло 117 правил, не было запланированным, потому что акцент на правила у нас выпадал на 2022 год. Безусловно, скорость реализации в коммерческом SOC была бы выше, даже несмотря на договорные процедуры и на то, что инфраструктуру так же нужно было бы подключать. Огромный минус – это поиск персонала. У нас есть несколько классных специалистов, которые двигают процесс. Но «хантинг» на рынке таких единичных специалистов является серьезной проблемой. Их на рынке практически и нет. Нужно владеть ситуацией, знать людей, контакты, чтобы находить тех, кто обладает необходимыми знаниями и навыками. Но и этого недостаточно. Чтобы людей привлечь, нужны всяческие поощрения, и не только материальные. Ведь эти специалисты, высококлассные профессионалы, должны захотеть к вам прийти, сказать: «О! Да тут здорово будет работать!». И вот эти ключевые фигуры являются главным подводным камнем, так как в один прекрасный момент такой человек может встать и пойти своим путем. Соответственно, надо заранее создавать кадровый резерв, готовить аналогичных по уровню специалистов. Другой подводный камень – понимание ответственными лицами, зачем и какой нужен SOC. Директор по информационной безопасности (CISO) должен отчетливо представлять, что он получит в результате и в каком виде. Если такого представления нет, то и полноценного результата не будет, независимо от того, идет речь о внутреннем или коммерческом SOC. Если у руководителя нет чёткого понимания необходимости создания своего SOC, то, скорее всего, системообразующий договор получится нежизнеспособным, как минимум, в первый год работы. Кроме того, специалист в области информационной безопасности обязан быть своего рода «переводчиком». Это значит, что он должен постоянно переводить с «технического уругвайского» на «бизнесовый парагвайский». Когда такой перевод происходит, бизнес начинает понимать, о чем идет речь, и выделяет деньги на то, что, как оказывается, для него полезно. Ну, и наконец, вера в свои силы. Да, это тоже важно, потому что где-то на полпути случается, что какие-то процессы идут медленно, что-то перестает получаться, или снова приходится переписывать ядро и т. п. Это демотивирует, и всегда нужно находить какие-то положительные моменты в том, что реализуется.
Автор:
Вячеслав Касимов, директор департамента информационной безопасности Московского кредитного банка (МКБ).
Интернет-портал «Безопасность пользователей в сети Интернет»
admin@safe-surf.ru
https://safe-surf.ru
