
Чем опасны процессорные уязвимости. Часть 2: Спекулятивные атаки
Введение
Во второй части рассказа про уязвимости процессоров обратимся к атакам на механизмы внеочередного и спекулятивного исполнения. Мы предполагали, что в атаках по побочным каналам нужная информация сама окажется в канале каким-либо образом. Для атак на основе спекулятивного исполнения это не является жестким условием – за счет упреждающего исполнения злоумышленник может сам доставить нужную ему информацию в канал. Как будет показано далее, описываемый класс атак позволяет злоумышленнику получить доступ к конфиденциальной информации жертвы, даже если ни одно из используемых программных решений не содержит недостатков и уязвимостей. Эти атаки обходят программную защиту от атак по побочным каналам и программные механизмы изоляции.
Практическая применимость атак
Атаки на упреждающее исполнение имеют свои ограничения. Например, некоторые из них ориентированы только на кражу данных ядра операционной системы, но не затрагивают других пользователей. Иные - атакуют защищенные анклавы, о которых также будет рассказано далее. Тем не менее, учитывая, что механизм упреждающего исполнения есть практически в каждом современном процессоре, атаки массово применимы и представляют опасность как для конечных пользователей, так и для крупных компаний, например, для облачных провайдеров. Более того, эти атаки не делают предположений о задачах атакуемых программ: данные могут быть украдены как из криптографического программного обеспечения, так и из ядра виртуальной машины пользователя облачного сервиса. Для многих из описанных атак уже существуют общедоступные примеры кода, подтверждающие их применимость. Исследователи, описывая каждую из атак, предлагают возможную реалистичную схему ее применения. Конечно, доведение атаки до рабочего состояния потребует от злоумышленника понимания устройства и механизмов процессора, а также систем, используемых в атакуемой среде. То есть, злоумышленнику потребуется теоретическая подготовка, но получить ее не составит труда, учитывая обилие доступных материалов. Отдельно заметим, что многие из таких атак применимы только для процессоров Intel. Но это не уменьшает риска, если учесть огромную долю рынка, занимаемой этой компанией.
Уязвимости, основанные на упреждающем исполнении
Как было отмечено ранее, упреждающее исполнение дает настолько большой выигрыш в производительности, что большинство современных процессоров используют механизмы спекулятивного и внеочередного исполнения. Если считать процессор «черным ящиком», то вероятность исполнения некорректной команды не ставит под сомнение защищенность устройства. Действительно, важно ли что исполняется, если код никак не задействует окружение и не вызывает побочных явлений? Но, как мы пояснили в первой части статьи, существуют эффективные методы извлечения данных процессора, причем некоторые из них не требуют физического вмешательства и прямого доступа к системе. Именно совместное использование побочных каналов (в основном побочного канала через кэш) и механизмов внеочередного исполнения сделали возможными атаки нового и очень опасного типа, что потребовало от разработчиков программного и аппаратного обеспечения серьезных усилий по их предотвращению.
Классификация атак на основе упреждающего исполнения
Атаки на основе упреждающего исполнения постоянно модифицируются, их новые варианты появляются очень быстро и в большом количестве. Разделим атаки на типы, учитывая сходство с самыми известными их предшественниками – атаками Meltdown и Spectre.
Атаки типа Meltdown
К атакам типа Meltdown отнесем атаки, в которых подразумевается наличие в программе злоумышленника инструкций, приводящих к вызову исключения в процессоре. Суть таких атак заключается в краже секретов до конечной обработки исключения процессором. Эти атаки позволяют «расплавить» аппаратные средства разделения процессов и уровней безопасности, отсюда и родилось название оригинальной атаки. Атаки типа Meltdown разделяют по используемым исключениям:- Device Not Available Exception (#NM) – возникает при работе с числами с плавающей точкой;
- Alignment Check Exception (#AC) – возникает при выявлении невыровненного операнда в памяти, если включена проверка выравнивания;
- Divide Error Exception (#DE) – ошибка при делении (деление на ноль или недостаток точности);
- Page-Fault Exception (#PF) – отказ страницы. Из-за большого количества вариаций, этот класс подразделяют по битам доступа, которые должны быть указаны для страницы:
- User/supervisor (U/S) – доступна ли страница пользователю или только суперпользователю (используется в оригинальной атаке Meltdown);
- Present (P) – находится ли страница в основной памяти (страница может быть сброшена на диск, если такая функция включена в процессоре);
- Read/write (R/W) – доступна ли запись в страницу;
- Protection Key (PK) – если установлен, то включена технология Memory Protection Keys, позволяющая контролировать доступ к адресам памяти пользователя. Обращение или запись к адресам, к которым доступ не предоставлен, приводит к отказу страницы;
- Execute-disable (XD) – возможно ли исполнять инструкции на данной странице;
- Supervisor-mode access prevention (SMAP, SM) – определяет, включен ли механизм SMAP. SMAP не позволяет коду уровня суперпользователя неявно использовать память пользователя, что помогает избежать атаки в случаях, когда программа пользователя использует уязвимость в коде программы суперпользователя и заставляет использовать свои данные;
- Invalid Opcode Exception, Undefined Opcode (#UD) – попытка выполнения некорректной инструкции;
- Stack Fault Exception (#SS) – ошибка при работе со стеком;
- BOUND Range Exceeded Exception (#BR) – исключение возникает, если не проходит проверка границ массива (то есть проверяемые индекс выходит за границы массива). Атаки данного класса можно подразделить по технологии проверки границ: инструкция BOUND (BND) или же расширение Memory Protection eXtensions (MPX);
- General Protection Exception (#GP) – широкий класс ошибок. Для атак типа Meltdown актуальна попытка считывания системных регистров. В этот класс попадает, например, атака Meltdown Variant 3a.
Атаки типа Spectre
К типу Spectre относят атаки, эксплуатирующие механизм спекулятивного исполнения. В них злоумышленник манипулирует внутренним состоянием процессора так, чтобы тот начал предсказывать дальнейшее выполнение выгодных злоумышленнику инструкций. При этом в программе злоумышленника и/или жертвы могут и не возникать исключения (например, оригинальная атака не приводит к возникновению исключений ни в программе злоумышленника, ни в программе жертвы, в отличие от Meltdown). Атаки типа Spectre позволяют обойти программную защиту от несанкционированного доступа к данным. При этом данные должны быть доступны атакуемой программе, что делает атаки типа Spectre похожими на проблему сonfused deputy, когда через некоторого посредника, обладающего доступом, получается считать данные, недоступные атакующему напрямую. В итоге, можно сказать, что атаки типа Spectre представляют собой способ создания побочного канала в случаях, где имеется программная защита от атак по побочным каналам. Такие атаки дополнительно разделяют по типам используемого для предсказания ветвлений микроахитектурного элемента:- Spectre-PHT использует буфер Pattern History Table (PHT) – буфер для предсказания перехода при условном ветвлении;
- Spectre-BTB использует буфер Branch Target Buffer (BTB) – буфер для предсказания косвенных переходов;
- Spectre-RSB использует буфер Return Stack Buffer (RSB) – буфер для предсказания адресов возврата (при выходе из функций);
- Spectre-STL использует механизм разрешения конфликтов (между операциями чтения и записи) в процессоре, который предсказывает зависимости Store To Load (STL) между обрабатываемыми данными. Процессор пытается заранее определить, зависит ли определенная операция чтения (Load) от предшествующей операции записи (Store). Это не всегда можно сделать абсолютно точно, так как вычисление адресов, соответствующих данным, может быть еще не завершено, поэтому и для этих операций в процессоре существует свой предсказатель. Если предсказывается, что чтение не зависит от записи, то данные могут быть сразу взяты из кэша L1d. В противном случае требуется дождаться завершения операции записи.
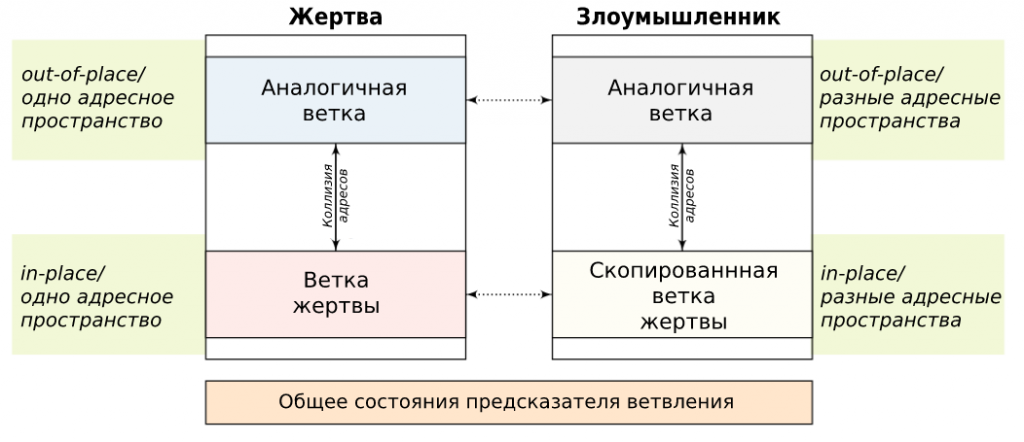
- Стратегия подготовки – как именно производится натренировка предсказателя: через другое адресное пространство (то есть в программе злоумышленника), или же в адресном пространстве самой жертвы (то есть злоумышленник натренировывает предсказатель, манипулируя программой-жертвой, например, через входные данные).
- Атакуемая ветка управления – какая ветка управления должна выполнится по замыслу злоумышленника: та же, что и натренированная – in-place (это может быть и ветка с тем же кодом в программе жертвы), или же аналогичная – out-of-place (натренировывается одна ветка, а спекулятивное исполнение эксплуатируется в другой, но с похожими признаками).
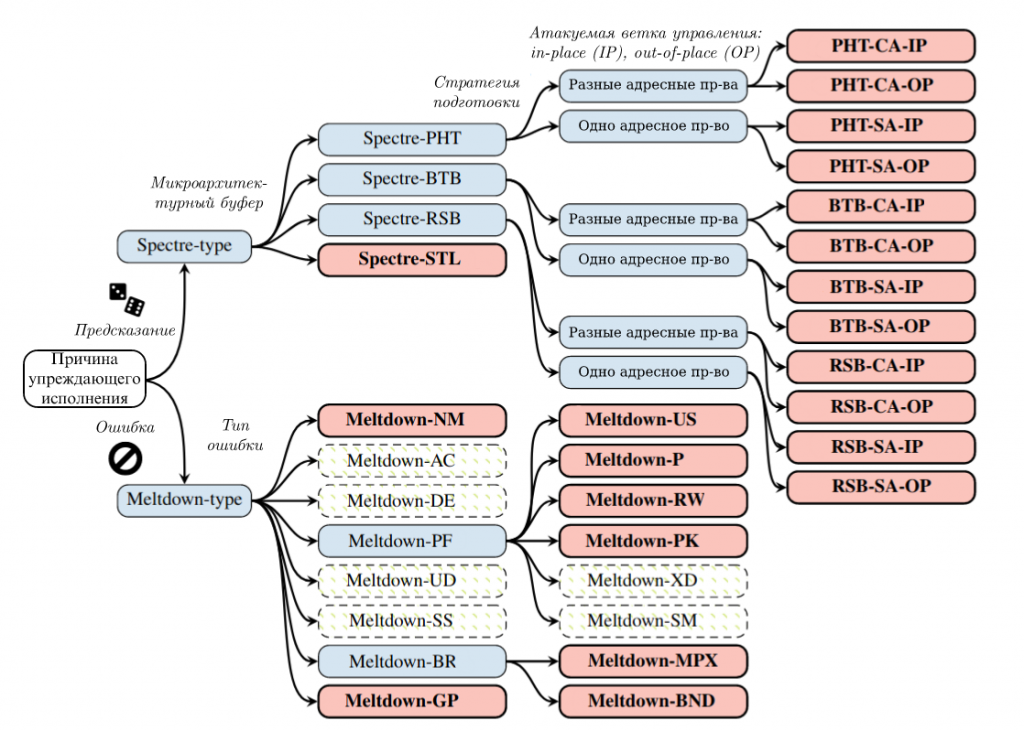
Классификация атак типа Meltdown и Spectre представлена ниже. Красным отмечены известные рабочие атаки, зеленымы штрихами – известные неприменимые атаки.
Meltdown и Spectre
Эти уязвимости были обнаружены в середине 2017 г. и поначалу сохранены в тайне, чтобы не допустить их эксплуатации до выпуска исправлений разработчиками операционных систем, а также обновлений микрокодов уязвимых процессоров. Дата публикации информации об уязвимостях была назначена на 9 января 2018 г. Планы нарушило то, что специалисты обратили внимание на массивные изменения в коде ядра ОС Linux. Далее последовали статьи и огласка в прессе, которые вызвали бурную реакцию на обнаруженные недостатки. Meltdown (CVE-2017-5754) была описана специалистами Google Project Zero, Cyberus Technology, а также Грацского технического университета. Цель атаки – память ядра, которое (для увеличения быстродействия) отображается целиком в адресное пространство процесса. В первую очередь процесс злоумышленника создает побочный канал через кэш. Для этого выделяется массив байтов размера 256 на 4096. Индексы строк соответствует всем возможным значениям одного байта (от 0 до 255). Большой объем данных по каждому индексу (4096 байтов) нужен лишь для устранения ложных срабатываний. Для ускорения последующих доступов к памяти процессор может кэшировать данные в окрестности затронутого адреса, но при этом не может перейти границу страницы памяти. Поэтому и используются данные размером в одну страницу памяти (как раз 4096 байтов). Важно, что массив не будет кэширован при создании. Далее исполняется следующий код:|
1 xor rax, rax 2 retry: 3 mov al, byte [rcx] 4 shl rax, 0xc 5 jz retry 6 mov rbx, qword [rbx + rax] |
- В регистр rax считывается байт из памяти ядра (строка 3).
- Из подготовленного массива считывается элемент (его размер не так важен) по индексу rax*4096, то есть из строки с тем индексом, какое значение имеет байт из памяти ядра (строка 6).
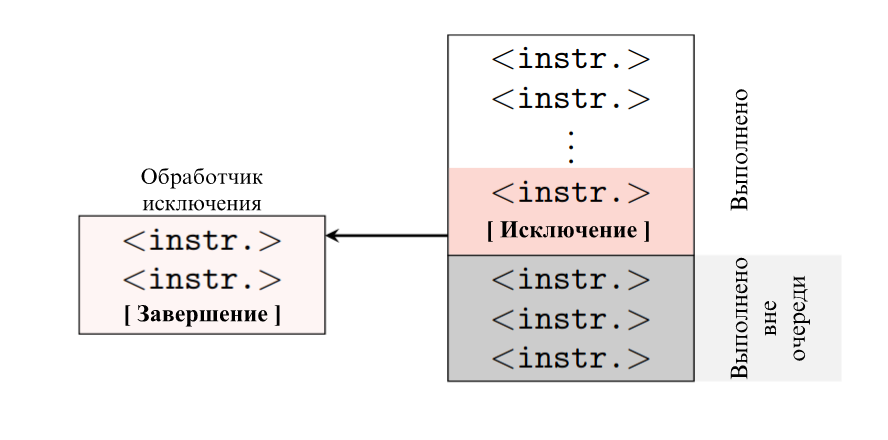
Исключение не даст проверить содержимое подготовленного массива, поэтому требуется избежать завершения программы. Первый способ – это создать процесс-потомок, который будет выполнять код выше. Тогда завершится только он, а процесс-родитель продолжит изучение массива. Кроме того, можно «погасить» исключение, поставив на сигнал об исключении обработчик, чтобы возникновение ошибки не приводило к завершению работы программы. Третье решение – использовать механизм Intel Transactional Synchronization Extensions (TSX), что позволяет работать с памятью посредством транзакций: серия операций либо выполняется целиком, либо же результаты частичного исполнения откатываются (например, при возникновении исключения), а работа программы не завершается.
Наконец, проверяется время доступа к строкам массива (по индексам n*4096) и замеряется время доступа. Один из элементов загрузится быстрее остальных – это и будет тот элемент, который считывался в коде выше. При первом считывании он был закэширован, поэтому во время проверки злоумышленник обратится к нему повторно, а значит, получит из кэша, а не оперативной памяти. Индекс этого элемента зависел от значения байта памяти ядра, поэтому этот байт легко восстанавливается.
Таким образом можно считать произвольный байт из памяти ядра, а значит и всю память целиком. При этом атака эффективна и не требует длительных операций.
Meltdown оказалась воспроизводима для процессоров Intel и Samsung Exynos M1, процессоры же AMD и ARM оказались устойчивы к атаке. Для устранения недостатка в процессорах Intel были выпущены обновления ОС и драйверов. Но, поскольку атака не использует программных уязвимостей, то полноценное исправление возможно только аппаратно. Intel на момент написания статьи уже выпустила модель процессора, защищенную от Meltdown, а также от Spectre.
Стоит упомянуть, что атака Meltdown - локальная и требует возможности запуска процесса на атакуемой машине.
Опаснее и мощнее оказалась атака Spectre, обнаруженная специалистами Google Project Zero, а также криптографом Полом Кёхером, который одним из первых обратил внимание на физические недостатки современных процессоров и сопутствующую им возможность утечки данных. В исследовании также участвовали и другие специалисты, полный список доступен на сайте, посвященном атакам Meltdown и Spectre.
Атака Meltdown изначально подразумевала только один вариант, но исследователи Spectre предложили сразу два сценария работы:
- Вариант 1 (CVE-2017-5753): нацелен на ошибочное предсказание условного ветвления;
- Вариант 2 (CVE-2017-5715): основан на косвенных переходах.
- Злоумышленник подготавливает побочный канал через кэш, а также тренирует предсказатель ветвлений на выполнение желаемой операции.
- Атакуемый процесс получает некоторый запрос от процесса-злоумышленника (этим запросом может быть, например, системный вызов, если атакуется ядро операционной системы) и начинает его обрабатывать. Во время обработки, за счет натренированного предсказателя ветвлений, атакуемый процесс спекулятивно считывает секретные данные, которые кэшируются.
- Атакующий восстанавливает данные из кэша.
|
if(x < array1_size) y = array2[array1[x]*4096]; |
- В коде процесса-злоумышленника дублируется код жертвы выше (если нет возможности натренировать ветку непосредственно в коде жертвы). Этот код выполняется много раз так, чтобы условие было истинным. Это натренирует предсказатель ветвления на выполнение так, как если бы условие было истинно.
- Процессу-жертве передается x = (адрес секретного байта k) - (адрес array1). Такой x, очевидно, не должен пройти проверку. Но данные в array1_size не находятся в кэше, поэтому проверка условия займет много времени. Процессор, натренированный на спекулятивное выполнение кода, следующим за условием, выполнит операцию заранее, и секретный байт k окажется в кэше.
- Далее злоумышленник обнаруживает изменения в кэше и находит секретный байт k.
- Отключение спекулятивного исполнения, но это ведет к серьезной потере производительности. Возможно отключение спекулятивного выполнения некоторых критичных участков за счет инструкций процессора.
- Ограничение спекулятивного доступа к секретным данным.
- Ограничение использования полученных в результате спекулятивных операций данных в инструкциях, которые могут привести к утечке.
- Усложнение восстановления данных через кэш, например, через ухудшение точности таймера.
- Исключение тренировки предсказателя косвенных переходов процессами из других доменов безопасности другими потоками; также можно предоставить возможность устанавливать барьер, который позволит игнорировать данные предсказателя, собранные до его установки. На момент написания данной статьи производители операционных систем и драйверов выпустили стабильные обновления безопасности, усложняющие проведение атак Meltdown и Spectre, а разработчики процессоров выпустили обновления микрокодов. Тем не менее, в отчете компании Google от 15 февраля 2019 г. отмечается, что обе проанализированные атаки фундаментальны, а исправления на программном уровне лишь усложняют эксплуатацию уязвимостей, но не делают ее невозможной. Как мы увидим далее, новые атаки, использующие схожие с Meltdown и Spectre концепты, действительно возможны даже при установленной защите от описанных уязвимостей. Описанные уязвимости получили оценку в 5.6 баллов. Meltdown и Spectre повлекли за собой появление ряда аналогичных атак, которые отнесены к целому классу одноименных атак. Сводка известных типов доступна здесь.
- Анклавы Intel SGX;
- Операционные системы и Режим системного управления;
- Гипервизоры.
- CVE-2018-12126 - MSBDS (Microarchitectural Store Buffer Data Sampling) - используется в атаке Fallout. Степень опасности определена в 6.5 баллов;
- CVE-2018-12127 - MLPDS (Microarchitectural Load Port Data Sampling) - используется в атаке RIDL. 6.5 баллов;
- CVE-2018-12130 - MFBDS (Microarchitectural Fill Buffer Data Sampling) - используется в атаках ZombieLoad и RIDL. 6.5 баллов;
- CVE-2019-11091 - MDSUM (Microarchitectural Data Sampling Uncacheable Memory) -используется в атаке RIDL. 3.8 баллов.
Foreshadow
Атака Foreshadow или L1 Terminal Fault (CVE-2018-3615 , CVE-2018-3620,CVE-2018-3646) последовала за атаками Meltdown и Spectre. Она основана на механизме внеочередного исполнения. Как мы увидим далее, атака требует присутствия сбоя при исполнении программы злоумышленника, что делает ее атакой типа Meltdown. Атака затрагивает:
Microarchitectural Data Sampling
Обнаружение Meltdown и Spectre привело к появлению множества работ на смежные темы. Эти атаки стали настоящим открытием для исследователей, ведь ранее было принято считать, что процессор – это изолированная среда. Уже было известно об утечке данных через кэш, но в таких утечках были в основном виноваты разработчики программного обеспечения. С момента же публикации работ о Meltdown и Spectre процессор перестал считаться недоступным «черным ящиком». Прошло полтора года с момента публикации первых статей об атаках. Были найдены новые сценарии применения атак, альтернативные подходы и другие решения. Компании выпустили программные исправления, разработчики процессоров начали вносить аппаратные исправления. Казалось, проблема исчерпана. Но в мае 2019 г. стало известно о ряде новых атак типа Meltdown, сформировавших класс Microarchitectural Data Sampling: ZombieLoad, RIDL и Fallout. Варианты этих атак способны обходить защиту от Meltdown и Spectre, в том числе и аппаратную. Так, например, вариант атаки ZombieLoad работает даже на новой архитектуре Intel Cascade Lake, защищенной от атак Meltdown и Spectre. Атаки основываются на уязвимостях:
Атаки описанного типа можно разделить по требованиям на порядок выполнения относительно жертвы. Для успешного проведения может оказаться достаточным запустить атаку на том же ядре, возможно, после смены контекста предыдущего процесса. Другие требуют выполнения не только на том же ядре, но и на соседнем потоке. Такие атаки полагаются на совместное использование буферов между гипертредами, механизм которых описан ранее.
Поскольку конкретные атаки в данном случае – не что иное, как ряд методик, позволяющих в итоге задействовать указанные выше уязвимости, остановимся на них подробнее.
Microarchitectural Store Buffer Data Sampling (MSBDS)
Store buffer или буфер хранения - микроархитектурная структура, служащая для хранения недавних операций записи, производимых процессором. Она нужна, в частности, для механизмов внеочередного и спекулятивного исполнения, чтобы избежать реальных записей в память во время внеочередного исполнения, и позволить быстро откатить изменения. Структура хранит в себе записи из адреса, по которому должна быть произведена запись, и данные. В случае тяжелых или ошибочных операций загрузки, описанных выше, исполняемые спекулятивно операции могут получить данные напрямую из буфера хранения, где они остались после прошлых операций, проводимых, например, другим процессом. Такое поведение называется store-to-load forwarding - данные из буфера хранения перенаправляются напрямую в буфер загрузки, если процессор считает, что между соответствующими данными есть зависимость. Злоумышленник, выполняя такую операцию загрузки, может получить доступ к остаточным данным другого процесса и далее восстановить их. Буфер хранения разделяется на непересекающиеся участки между гипертредами, поэтому атаковать соседний гипертред возможности нет. Тем не менее, если соседний поток засыпает, буфер отдается выполняемому потоку целиком, что позволяет извлечь сохранившиеся данные. В то же время, проснувшийся поток снова поделит буфер, захватывая сохранившиеся данные активного потока, что также может привести к утечке.
Microarchitectural Fill Buffer Data Sampling (MFBDS)
Fill Buffer или буфер заполнения - структура, используемая для загрузки данных для обработки на процессоре. Структура необходима для реализации механизма неблокирующего кэша L1D – ожидая получения данных, такой кэш может использоваться для других операций с памятью. При кэш-промахе в буфере заполнения аллоцируется область, куда требуемые данные будут загружены. То же самое происходит для операций работы с системой ввода-вывода и некэширумой памятью. Данные из буфера могут быть записаны в кэш, но, кроме этого, они также могут быть переданы в буфер загрузки напрямую. Как и в случае MSBDS, описанном выше, злоумышленник может запустить механизм спекулятивного исполнения: выполнить тяжелую или ошибочную операции загрузки, требующую дополнительных действий со стороны процессора и запуска микрокода. При этом остальные инструкции программы злоумышленника продолжат выполняться, но спекулятивно, а вместо валидных данных, которые будут получены только после завершения упомянутой операции загрузки, процессор может предоставить данные из буфера заполнения – это могут быть и чужие данные. Далее злоумышленник сможет восстановить эти данные через кэш. Буфер заполнения не разделяется между гипертредами, а используется ими совместно. Это позволяет процессу-злоумышленнику следить за получаемыми соседом данными из памяти. С этой уязвимостью схожа другая, L1D Eviction Sampling (CVE-2020-0549), используемая в атаке CacheOut. Вытесняемые из кэша L1D данные, при некоторых условиях, записываются в буфер заполнения, откуда они могут быть считаны злоумышленником точно так же, как и в случае уязвимости MFBDS.
Microarchitectural Load Port Data Sampling (MLPDS)
Load ports или порты загрузки - структура-посредник между памятью и регистровым файлом. Перед тем, как попасть в регистровый файл из памяти или же с устройств ввода-вывода, данные записываются в порт загрузки, затирая прошлые данные. Реализация Intel не подразумевает очистки данных из порта загрузки, полагаясь на последующую перезапись. Кроме того, выполняемые операции получат из порта загрузки только то количество бит, которое этой операцией подразумевается. Важно заметить, что современные процессоры имеют векторные расширения, то есть набор инструкций, позволяющий использовать большие (до 512 бит, а в будущих моделях возможно и более) векторные регистры. Порты загрузки должны вмещать в себе любой из доступных размеров регистров. Данные из портов загрузки, аналогично прошлым случаям, могут быть переданы напрямую спекулятивным операциям. Если в портах загрузки находились данные другого процесса, то это приведет к утечке. Порты загрузки, как и буферы заполнения, используются гипертредами совместно, поэтому один поток может атаковать другой на том же физическом ядре.
Microarchitectural Data Sampling Uncacheable Memory (MDSUM)
Данная уязвимость не является концептуально новой. В данном случае лишь отмечается, что работа с некэшируемой памятью также может привести к спекулятивному использованию данных из микроархитектурных буферов, описанных ранее.
Исправление недостатков
Конечно, полноценное исправление уязвимости требует внесения аппаратных изменений, предотвращающих считывание остаточных данных. Заметим, что программная очистка будет эффективна только для случая MSBDS, поскольку во всех остальных случаях поток может снова перезагрузить данные сразу после удаления остаточной информации, и они вновь будут доступны злоумышленнику. Intel внесла исправления в микрокод, добавляющие некоторым инструкциям функциональность очистки буферов. Кроме того, возможно исполнение последовательностей инструкций для очистки. Очевидное решение, исключающее кражу информации соседствующим потоком, состоит в отключении механизма одновременной многопоточности. Как и ранее, этот вариант приводит к серьезной потере производительности (до 40%), что во многих случаях неприемлемо. Некоторые программные механизмы позволяют избежать атак между гипертредами. Первый из них, Group Scheduling, заключается в выполнении на одном физическом ядре только потоков, доверяющих друг другу (например, потоков одного процесса). Это позволяет избежать атак между пользователями. Схемы, приведенные ниже, показывают распределение потоков по логическим ядрам, где потоки разного цвета принадлежат разным доменам безопасности.
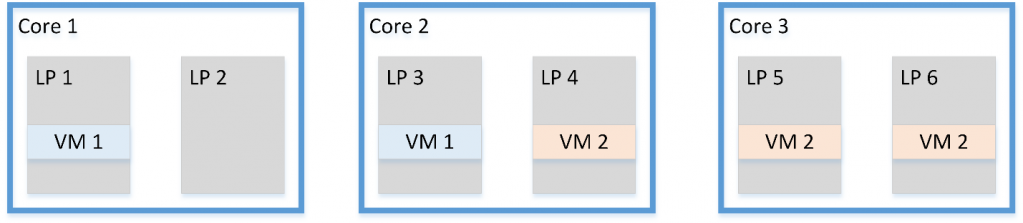
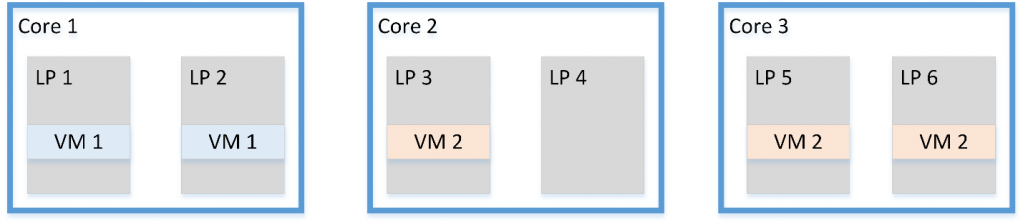
Другой механизм предлагает последовательность действий для исключения утечки данных ядра. На схеме, изображенной ниже, рассматриваются все возможные переходы между исполнением пользовательской программы и кодом ядра ОС:
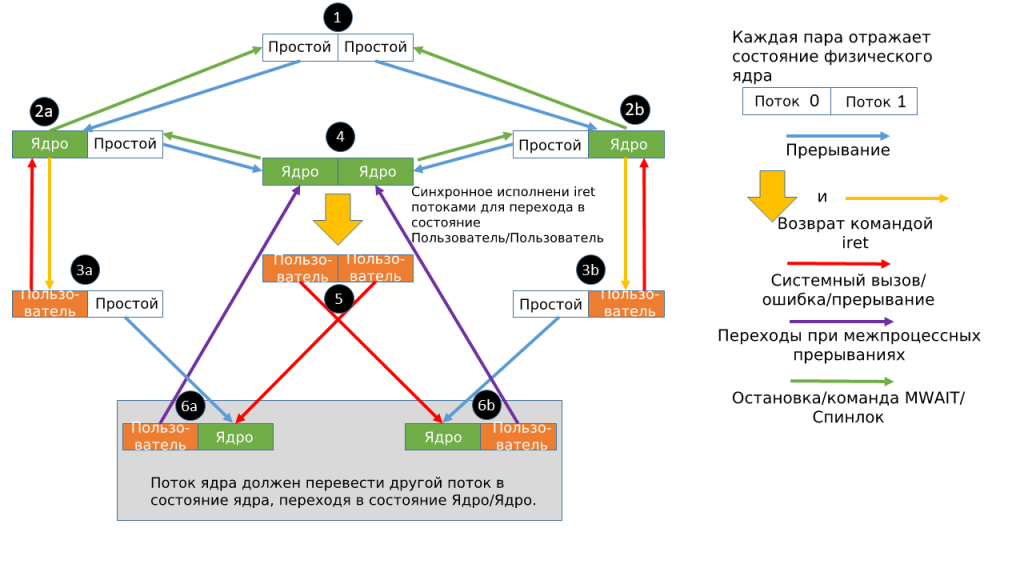
При передаче управления с ядра на процесс пользователя предполагается очистка микроархитектурных буферов. В ситуациях 6a и 6b ядро должно избегать обработки секретных данных. Если же необходимо провести операцию с секретными данными, то ядро должно перевести управление на соседнем потоке также на ядро и прийти в ситуацию 4. Этого можно добиться, используя межпроцессорные прерывания (interprocessor interrupt, IPI).
Для анклавов Intel SGX защитная мера – это запрет выполнения при включенном гипертрединге. При этом процессором производится удаленная аттестация, которая определяет, в частности, включена ли одновременная многопоточность на проверяемой системе. Риск атаки между потоками в таком случае определяет проверяющий. Он же определяет, можно ли запустить анклав на проверяемой системе.
Заключение
Мы познакомились с некоторыми примерами уязвимостей современных процессоров, которые являются следствием многочисленных оптимизационных надстроек в процессорах. Стоит заметить, что причина этих проблем – не сами алгоритмы оптимизации, а скорее их реализация. Действительно, механизмы внеочередного и спекулятивного исполнения не представляли бы опасности, если бы не оставляли никакого, даже микроархитектурного, следа после отката результатов. Предложить исправление, которое подошло бы всем производителям, крайне затруднительно. Устранение найденных недостатков может оказаться недостаточно полным и оставить некоторые лазейки и дыры в безопасности, как, например, в случае с архитектурой Intel Cascade Lake. Полноценное избавление от недостатков потребует пересмотров текущих архитектурных решений и устоявшихся практик увеличения производительности. Ситуацию усугубляет отсутствие исчерпывающей документации устройства процессоров. Проприетарные технологии не могут быть проанализированы со стороны, а компания-производитель вряд ли будет возвращаться к вопросу безопасности после проведения полноценного тестирования на этапе разработки. Тем не менее, существуют механизмы защиты от упомянутых атак. Многие были описаны выше, но есть и ряд других практик. Например, хороший метод защиты - устранение побочного канала через кэш, который используется в большинстве атак. Разделение кэш-памяти на недоступные другим процессам зоны, аналогично оперативной памяти, не позволило бы отслеживать действия жертвы через кэш. Такая технология уже используется в некоторых процессорах Intel. Но данное решение приводит к дополнительным проверкам, а вероятность атаки сохраняется, например, если жертва и злоумышленник используют общую разделяемую библиотеку, данные из которой кэшируются в область, доступную обоим процессам. При этом некоторые исследования показывают, что такое решение, наоборот, увеличивает производительность кэшей, поскольку не происходит конфликтов, а записи разных процессов не затирают друг друга. Внедрение механизмов оптимизации без учета рисков безопасности привело к серьезным последствиям, пошатнувшим репутацию компаний и повлекших большие убытки. Но есть и хорошая новость: исследователи безопасности процессоров обратили внимание на эту проблему и продолжают в упреждающем режиме искать новые пути кражи данных, чтобы их закрыть. В настоящее время нет статистики, использовались ли рассмотренные нами уязвимости для реальных атак, и сколько данных утекло из-за них. Но, зная о существовании проблемы, компании совместно с исследователями разрабатывают решения для закрытия дыр безопасности и, в конечном итоге, для выпуска защищенных устройств. Авторы:Григорий Дороднов, исследователь безопасности, ООО «СолидСофт»,
Денис Гамаюнов, зав. лабораторией интеллектуальных систем кибербезопасности, ВМК МГУ имени М.В. Ломоносова
Интернет-портал «Безопасность пользователей в сети Интернет»
admin@safe-surf.ru
https://safe-surf.ru
